【python爬虫】80页md笔记0基础到scrapy项目高手,第(4)篇:requests和网络数据获取进阶

本阶段主要学习requests这个http模块,该模块主要用于发送请求响应,该模块有很多的替代模块,比如说urllib模块,但是在工作中用的最多的还是requests模块,requests的代码简洁易懂,相对于臃肿的urllib模块,使用requests编写的爬虫代码将会更少,而且实现某一功能将会简单。因此建议大家掌握该模块的使用。
整套爬虫笔记直接地址: 请移步这里
共 8 章,37 子模块,总计近6w字
接上一篇
4. requests模块发送post请求
思考:哪些地方我们会用到POST请求? 1. 登录注册( 在web工程师看来POST 比 GET 更安全,url地址中不会暴露用户的账号密码等信息) 2. 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
4.1 requests发送post请求的方法
response = requests.post(url, data)data参数接收一个字典- requests 模块发送post请求函数的其它参数和发送get请求的参数完全一致
4.2 POST请求练习
下面面我们通过金山翻译的例子看看post请求如何使用:
1. 地址:ht://fy.iciba.com/>
思路分析
1. 抓包确定请求的url地址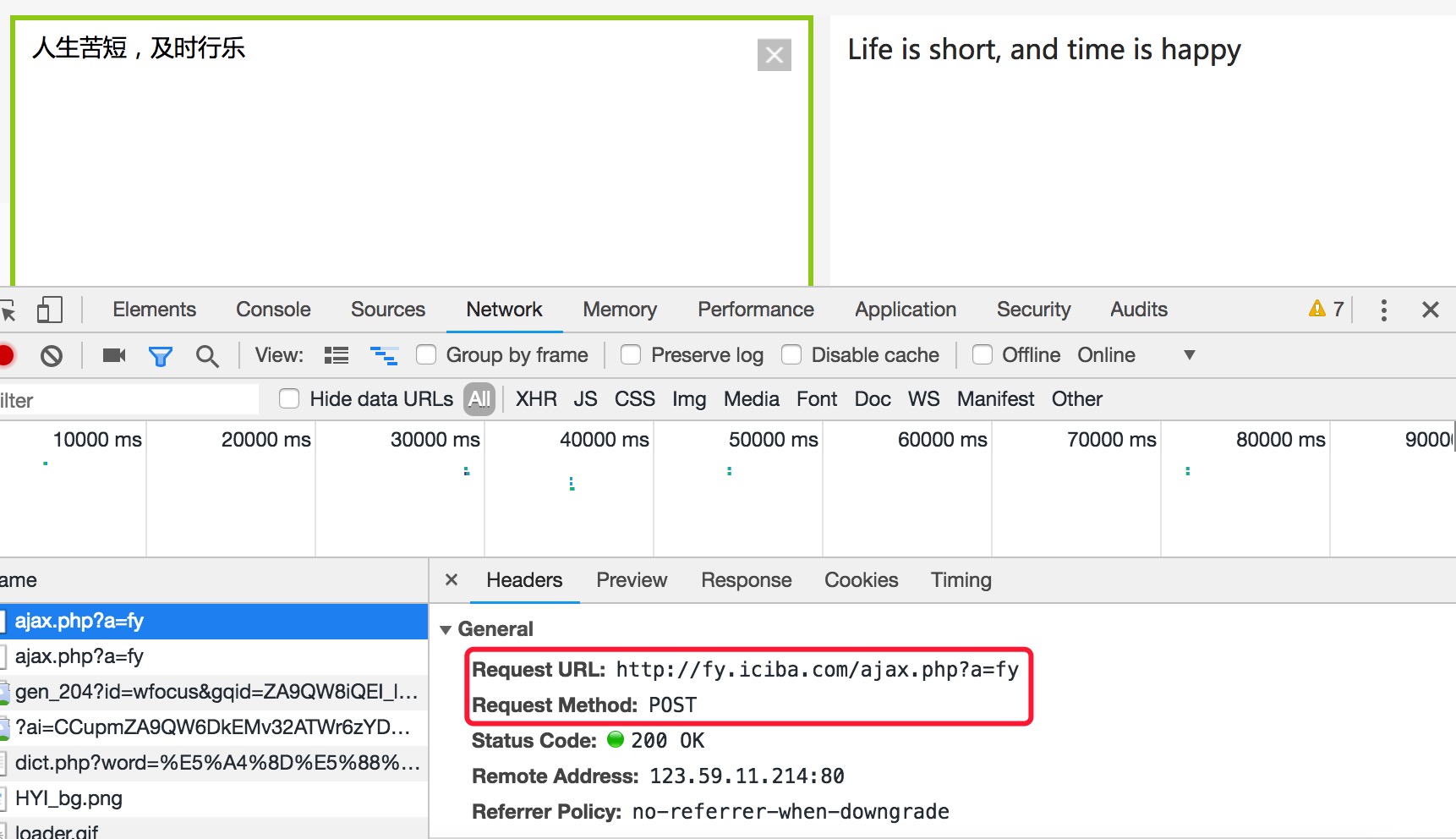
2. 确定请求的参数
3. 确定返回数据的位置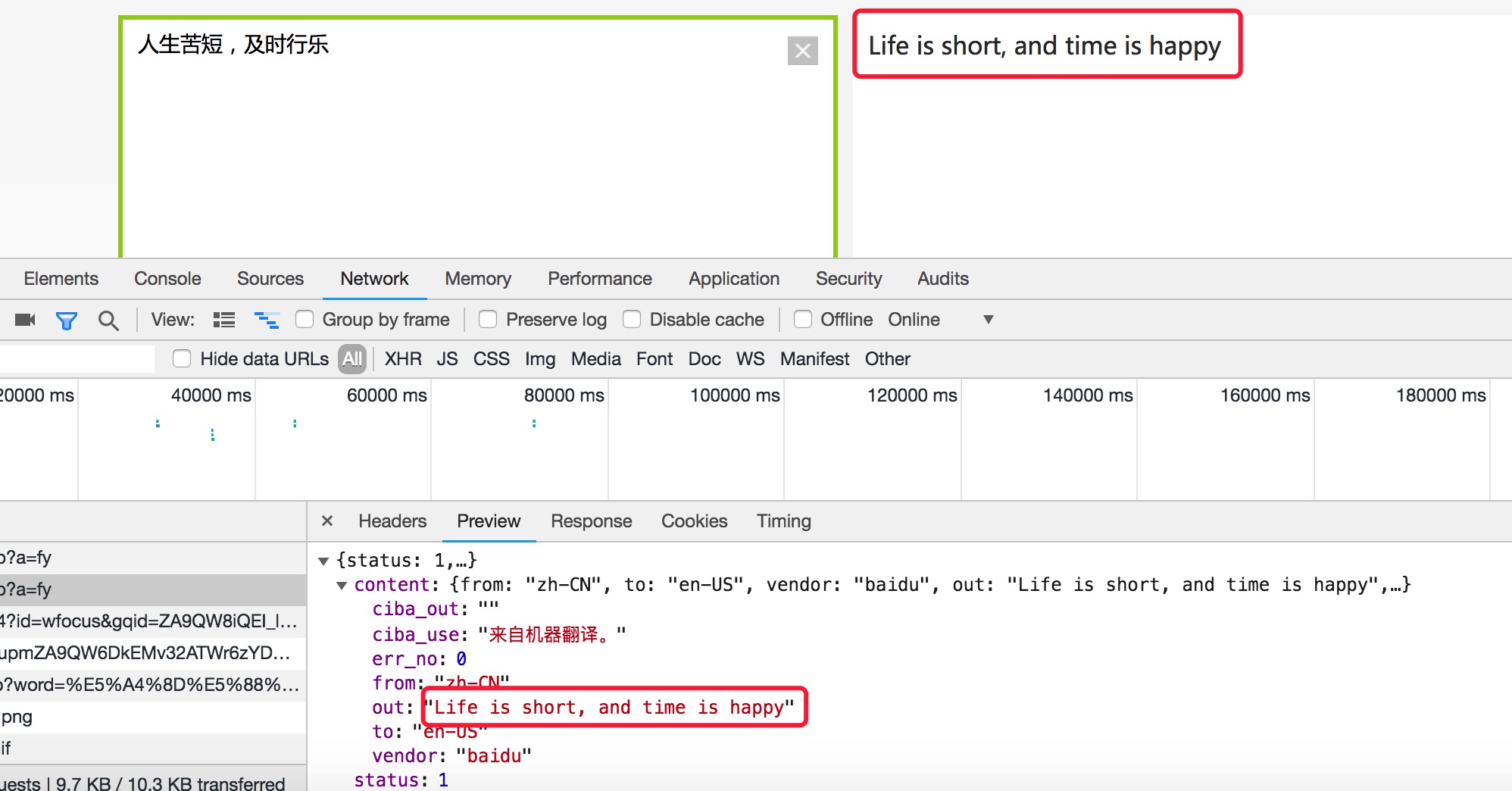
4. 模拟浏览器数据4.2.3 抓包分析的结论
- url地址:
ht://fy.iciba.com/ - 请求方法:POST
- 请求所需参数:
data = {
'f': 'auto', # 表示被翻译的语言是自动识别
't': 'auto', # 表示翻译后的语言是自动识别
'w': '人生苦短' # 要翻译的中文字符串
}
- pc 端User-Agent
4.2.4 代码实现
了解requests模块发送post请求的方法,以及分析过移动端的百度翻译之后,我们来完成代码
import requests
import json
class King(object):
def __init__(self, word):
self.url = "http://fy.iciba.com/ajax.php?a=fy"
self.word = word
self.headers = {
"User-Agent": ""
}
self.post_data = {
"f": "auto",
"t": "auto",
"w": self.word
}
def get_data(self):
response = requests.post(self.url, headers=self.headers, data=self.post_data)
# 默认返回bytes类型,除非确定外部调用使用str才进行解码操作
return response.content
def parse_data(self, data):
# 将json数据转换成python字典
dict_data = json.loads(data)
# 从字典中抽取翻译结果
try:
print(dict_data['content']['out'])
except:
print(dict_data['content']['word_mean'][0])
def run(self):
# url
# headers
# post----data
# 发送请求
data = self.get_data()
# 解析
self.parse_data(data)
if __name__ == '__main__':
# king = King("人生苦短,及时行乐")
king = King("China")
king.run()
# python标准库有很多有用的方法,每天看一个标准库的使用知识点:掌握 requests模块发送post请求
5. 利用requests.session进行状态保持
requests模块中的Session类能够自动处理发送请求响应过程中产生的cookie,进而达到状态保持的目的。接下来我们就来学习它
5.1 requests.session的作用以及应用场景
- requests.session的作用
- 自动处理cookie,即 下 一次请求会带上前一次的cookie
- requests.session的应用场景
- 自动处理连续的多次请求过程中产生的cookie
5.2 requests.session使用方法
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
session = requests.session() # 实例化session对象
response = session.get(url, headers, ...)
response = session.post(url, data, ...)- session对象发送get或post请求的参数,与requests模块发送请求的参数完全一致
5.3 课堂测试
使用requests.session来完成github登陆,并需要登陆后才能访问的页面
5.3.1 提示
1. 对github登陆以及访问登陆后才能访问的页面的整个完成过程进行抓包
2. 确定登陆请求的url地址、请求方法和所需的请求参数
* 部分请求参数在别的url对应的响应内容中,可以使用re模块
3. 确定登陆后才能访问的页面的的url地址和请求方法
4. 利用requests.session完成代码5.3.2 参考代码
import requests
import re
# 构造请求头字典
headers = {
'User-Agent': '',
}
# 实例化session对象
session = requests.session()
# 访问登陆页登陆请求所需参数
response = session.get('https://github.com/login', headers=headers)
authenticity_token = re.search('name="authenticity_token" value="(.*?)" />
', response.text).group(1) # 使用正则登陆请求所需参数
# 构造登陆请求参数字典
data = {
'commit': 'Sign in', # 固定值
'utf8': '✓', # 固定值
'authenticity_token': authenticity_token, # 该参数在登陆页的响应内容中
'login': input('输入github账号:'),
'password': input('输入github账号:')
}
# 发送登陆请求(无需关注本次请求的响应)
session.post('https://github.com/session', headers=headers, data=data)
# 打印需要登陆后才能访问的页面
response = session.get('https://github.com/1596930226', headers=headers)
print(response.text)知识点:掌握 利用requests.session进行状态保持
数据提取概
本阶段本文主要学习响应之后如何从响应中提取我们想要的数据,在本阶段本文中我们会讲解一些常用的方法和模块,基本上我们以后遇到的情况在掌握本阶段本文之后都能搞定
数据提取概述
知识点
- 了解 响应内容的分类
- 了解 xml和html的区别
1. 响应内容的分类
在发送请求响应之后,可能存在多种不同类型的响应内容;而且很多时候,我们只需要响应内容中的一部分数据
- 结构化的响应内容
- json字符串
- 可以使用re、json等模块来提取特定数据
- json字符串的例子如下图
- xml字符串
- 可以使用re、lxml等模块来提取特定数据
- xml字符串的例子如下 bookstore> book category="COOKING"> title lang="en"> Everyday Italian/title> author> Giada De Laurentiis/author> year> 2005/year> price> 30.00/price> /book> book category="CHILDREN"> title lang="en"> Harry Potter/title> author> J K. Rowling/author> year> 2005/year> price> 29.99/price> /book> book category="WEB"> title lang="en"> Learning XML/title> author> Erik T. Ray/author> year> 2003/year> price> 39.95/price> /book> /bookstore>
- json字符串
- 非结构化的响应内容
- html字符串
- 可以使用re、lxml等模块来提取特定数据
- html字符串的例子如下图
- html字符串
知识点:了解 响应内容的分类
2. 认识xml以及和html的区别
要搞清楚html和xml的区别,首先需要我们来认识xml
2.1 认识xml
xml是一种可扩展标记语言,样子和html很像,功能更专注于对传输和存储数据
bookstore>
book category="COOKING">
title lang="en">
Everyday Italian/title>
author>
Giada De Laurentiis/author>
year>
2005/year>
price>
30.00/price>
/book>
book category="CHILDREN">
title lang="en">
Harry Potter/title>
author>
J K. Rowling/author>
year>
2005/year>
price>
29.99/price>
/book>
book category="WEB">
title lang="en">
Learning XML/title>
author>
Erik T. Ray/author>
year>
2003/year>
price>
39.95/price>
/book>
/bookstore>
上 面的xml内容可以表示为下面的树结构:
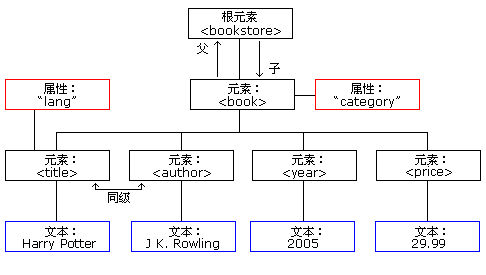 xml树结构
xml树结构2.2 xml和html的区别
二者区别如下图
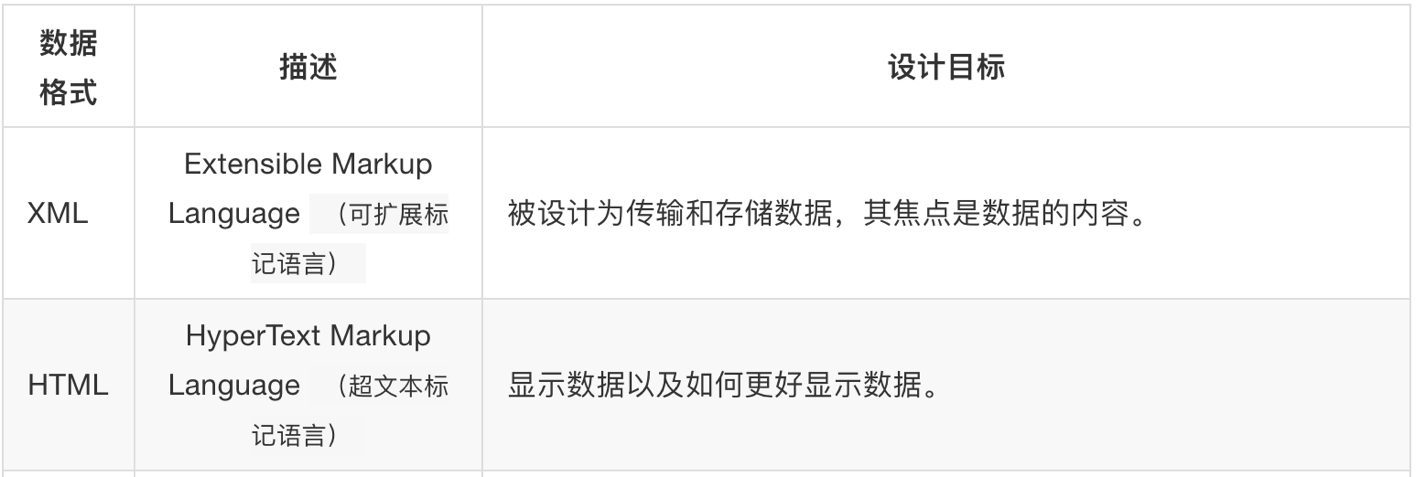 xml和html的区别
xml和html的区别- html:
- 超文本标记语言
- 为了更好的显示数据,侧重点是为了显示
- xml:
- 可扩展标记语言
- 为了传输和存储数据,侧重点是在于数据内容本身
知识点:了解 xml和html的区别
2.3 常用数据解析方法
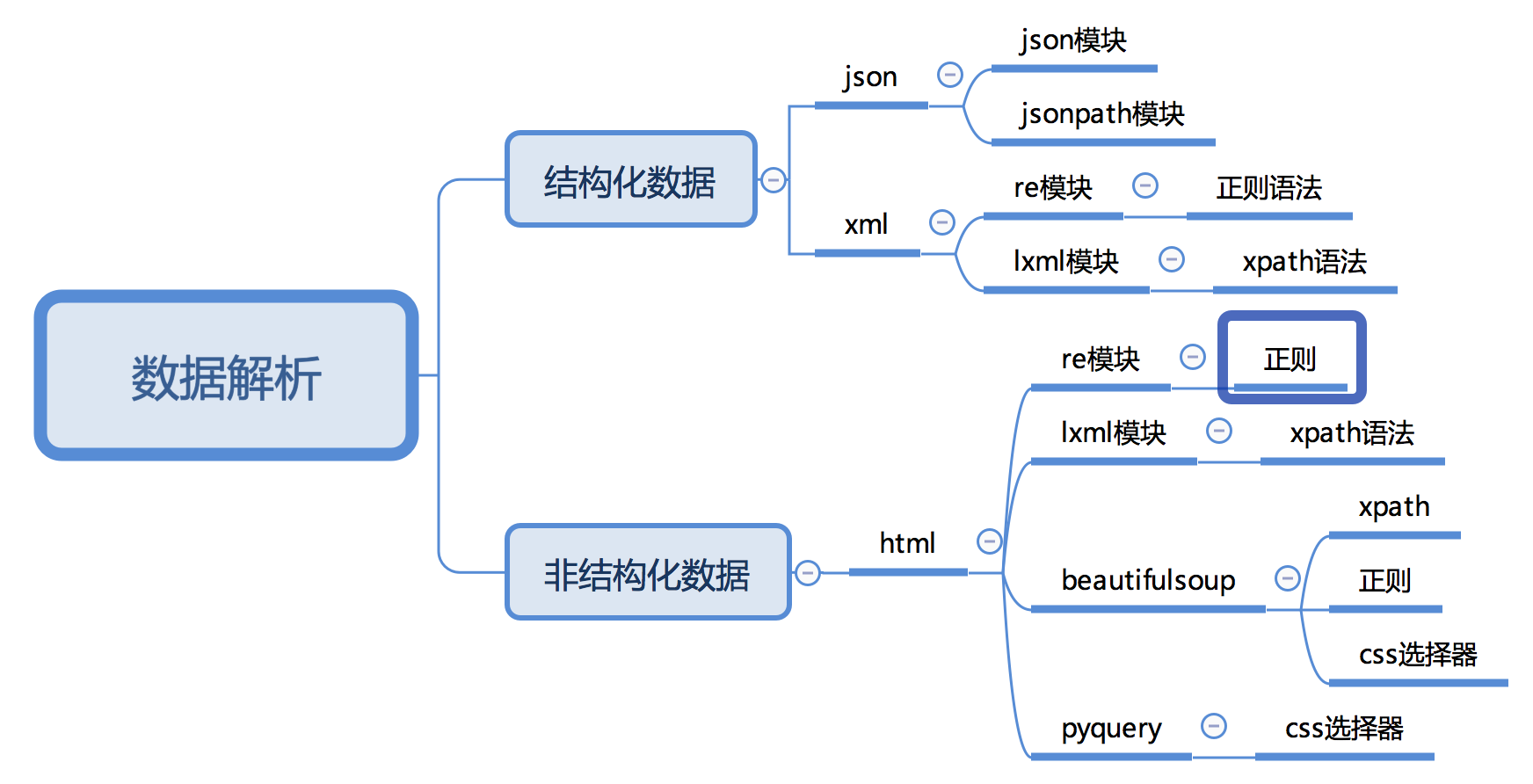 常用数据解析方法
常用数据解析方法数据提取-jsonpath模块
知识点
- 了解 jsonpath模块的使用场景
- 掌握 jsonpath模块的使用
1. jsonpath模块的使用场景
如果有一个多层嵌套的复杂字典,想要根据key和下标来批量提取value,这是比较困难的。jsonpath模块就能解决这个痛点,接下来我们就来学习jsonpath模块
jsonpath 可以按照key对python字典进行批量数据提取
知识点:了解 jsonpath模块的使用场景
2. jsonpath模块的使用方法
2.1 jsonpath模块的安装
jsonpath是第三方模块,需要额外安装
pip install jsonpath
2.2 jsonpath模块提取数据的方法
from jsonpath import jsonpath ret = jsonpath(a, 'jsonpath语法规则字符串')
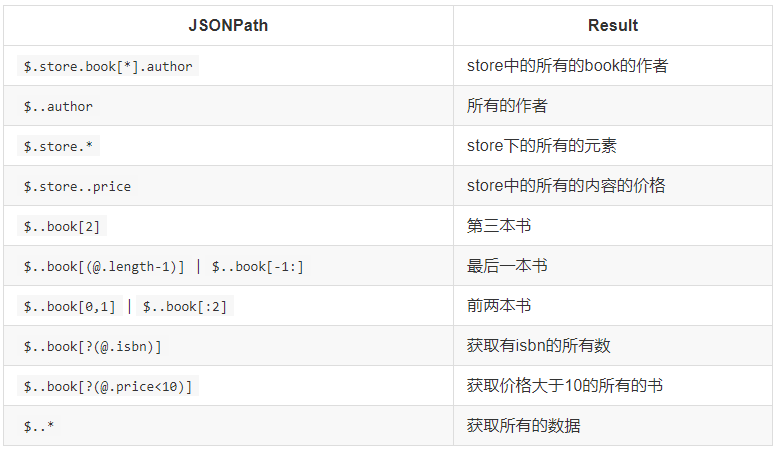
2.3 jsonpath语法规则
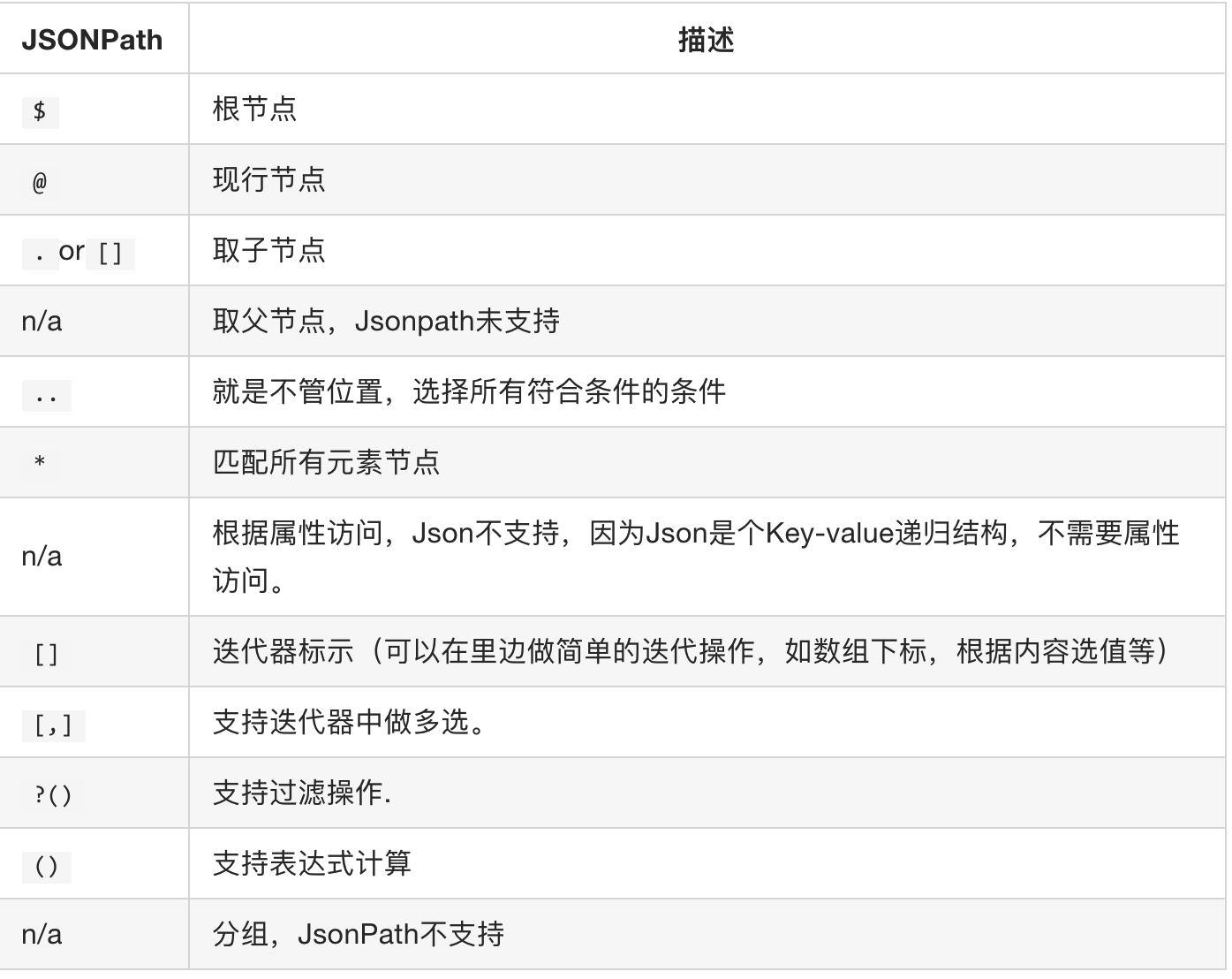 jsonpath的方法
jsonpath的方法2.4 jsonpath使用示例
book_dict = { "store": { "book": [ { "category": "reference", "author": "Nigel Rees", "title": "Sayings of the Century", "price": 8.95 } , { "category": "fiction", "author": "Evelyn Waugh", "title": "Sword of Honour", "price": 12.99 } , { "category": "fiction", "author": "Herman Melville", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 } , { "category": "fiction", "author": "J. R. R. Tolkien", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } } } from jsonpath import jsonpath print(jsonpath(book_dict, '$..author')) # 如果取不到将返回False # 返回列表,如果取不到将返回False
 jsonpath使用示例
jsonpath使用示例3. jsonpath练习
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,所有城市的名字的列表,并写入文件。
参考代码:
import requests import jsonpath import json
# 拉勾网城市json字符串
url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
headers = {
"User-Agent": ""}
response =requests.get(url, headers=headers)
html_str = response.content.decode()
# 把json格式字符串转换成python对象
jsonobj = json.loads(html_str)
# 从根节点开始,所有key为name的值
citylist = jsonpath.jsonpath(jsonobj,'$..name')
# 写入文件
with open('city_name.txt','w') as f:
content = json.dumps(citylist, ensure_ascii=False)
f.write(content)知识点:掌握 jsonpath模块的使用
未完待续 下一期下一章
完整笔记请看文章开头
点击关注作者,阅读全文声明:本文内容由网友自发贡献,本站不承担相应法律责任。对本内容有异议或投诉,请联系2913721942#qq.com核实处理,我们将尽快回复您,谢谢合作!
若转载请注明出处: 【python爬虫】80页md笔记0基础到scrapy项目高手,第(4)篇:requests和网络数据获取进阶
本文地址: https://pptw.com/jishu/571582.html