【python爬虫笔记】0基础到scrapy高手,第(5)篇:爬虫数据提取之lxml和xpath

本文主要学习一下关于爬虫的相关前置知识和一些理论性的知识,通过本文我们能够知道什么是爬虫,都有那些分类,爬虫能干什么等,同时还会站在爬虫的角度复习一下http协议。
全套python爬虫笔记地址: 请移步这里
共 8 大章,37 子模块,总计 5.6w 字
数据提取概要
本阶段本文主要学习响应之后如何从响应中提取我们想要的数据,在本阶段本文中我们会讲解一些常用的方法和模块,基本上我们以后遇到的情况在掌握本阶段本文之后都能搞定
数据提取-lxml模块
知识点
- 了解 lxml模块和xpath语法的关系
- 了解 lxml模块的使用场景
- 了解 lxml模块的安装
- 了解 谷歌浏览器xpath helper插件的安装和使用
- 掌握 xpath语法-基础节点选择语法
- 掌握 xpath语法-节点修饰语法
- 掌握 xpath语法-其他常用语法
- 掌握 lxml模块中使用xpath语法定位元素提取属性值或文本内容
- 掌握 lxml模块中etree.tostring函数的使用
1. 了解 lxml模块和xpath语法
对html或xml形式的文本提取特定的内容,就需要我们掌握lxml模块的使用和xpath语法。
- lxml模块可以利用XPath规则语法,来快速的定位HTML\XML 文档中特定元素以及节点信息(文本内容、属性值)
- XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的 语 言,可用来在 HTML\XML 文档中对 元 素和属性进行遍历。
- W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
- 提取xml、html中的数据需要lxml模块和xpath语法配合使用
知识点:了解 lxml模块和xpath语法
2. 谷歌浏览器xpath helper插件的安装和使用
要想利用lxml模块提取数据,需要我们掌握xpath语法规则。接下来我们就来了解一下xpath helper插件,它可以帮助我们练习xpath语法
2.1 谷歌浏览器xpath helper插件的作用
在谷歌浏览器中对当前页面测试xpath语法规则
2.2 谷歌浏览器xpath helper插件的安装和使用
我们以windos为例进行xpath helper的安装
2.2.1 xpath helper插件的安装
- 下载Chrome插件 XPath Helper
* 可以在chrome应用商城进行下载,如果无法下载,也可以从下面的链接进行下载
* 下载地址:https://pan.baidu.com/s/1UM94dcwgus4SgECuoJ-Jcg>
密码:337b- 把文件的后缀名crx改为rar,然后解压到同名文件夹中
- 把解压后的文件夹拖入到已经开启开发者模式的chrome浏览器扩展程序界面
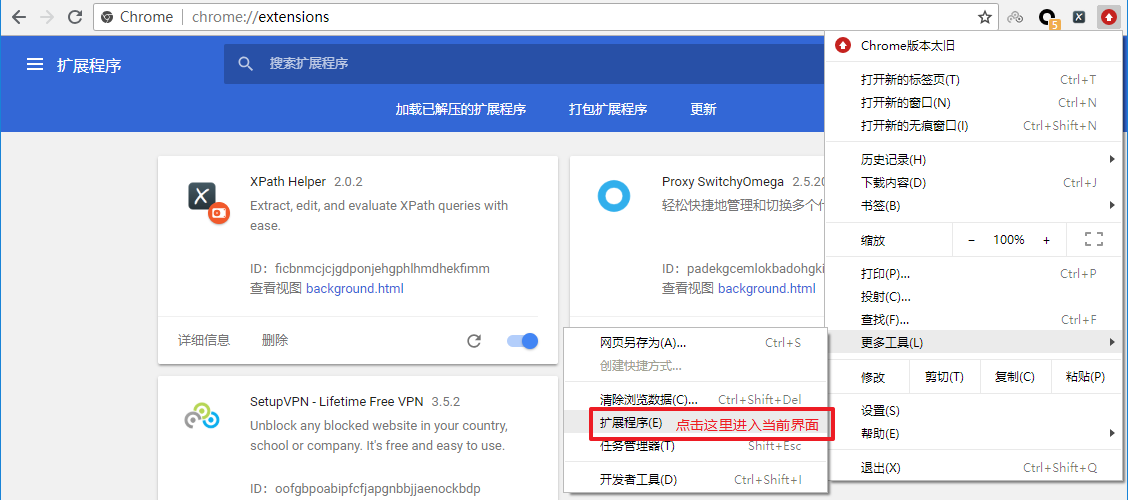 xpath_helper插件安装-1
xpath_helper插件安装-1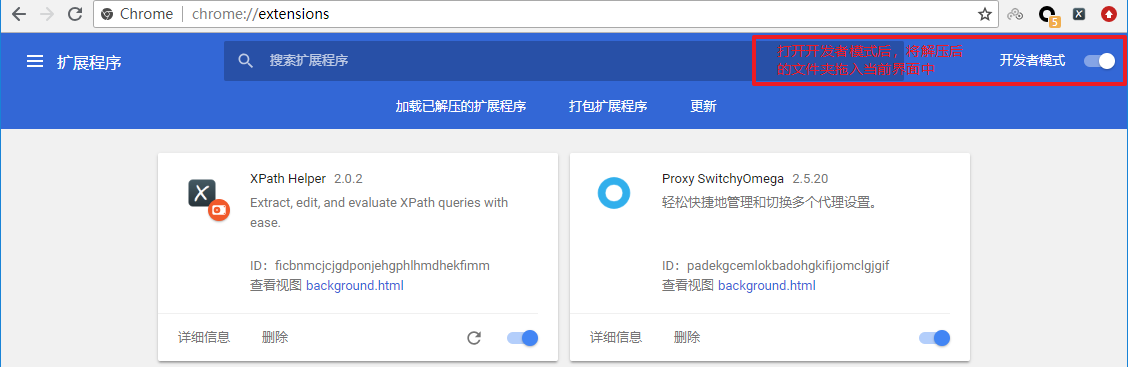 xpath_helper插件安装-2
xpath_helper插件安装-2- 重启浏览器后,访问url之后在页面中点击xpath图标,就可以使用了
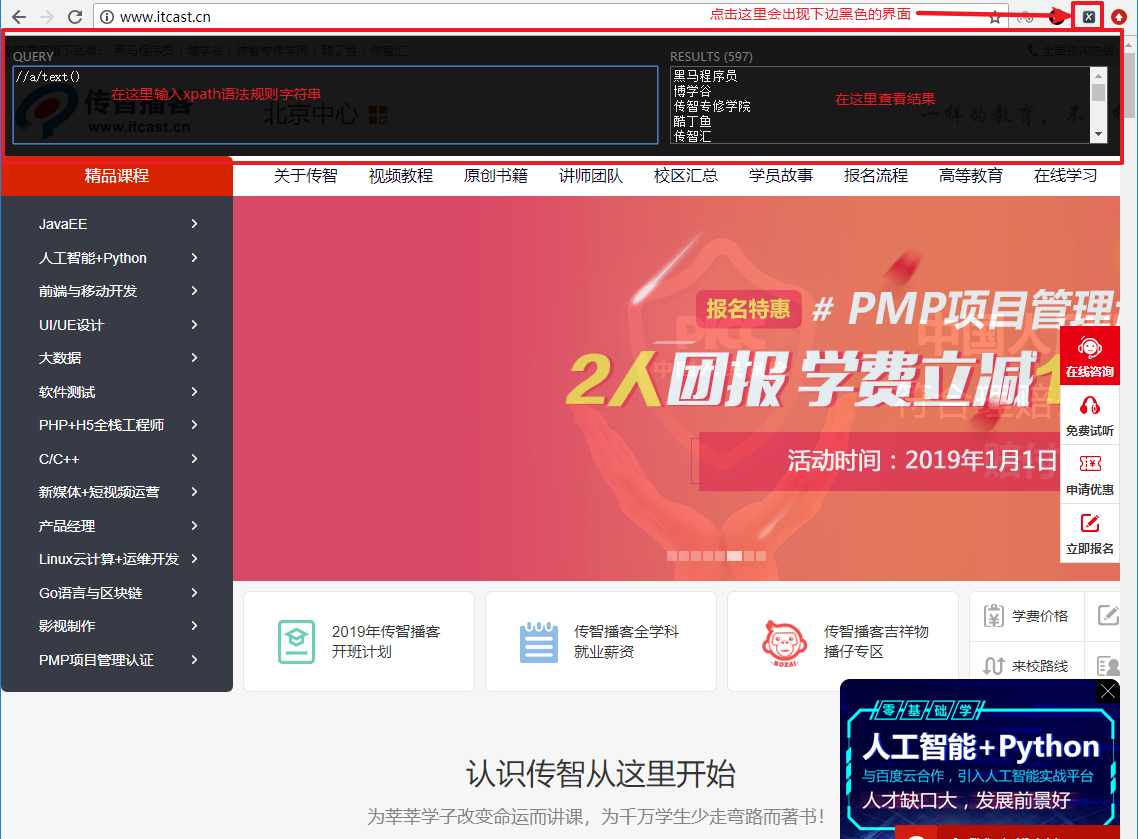 xpath_helper插件安装-3
xpath_helper插件安装-3- 如果是 linux 或macOS操作系统,无需操作上述的步骤2,直接将crx文件拖入已经开启开发者模式的chrome浏览器扩展程序界面
知识点:了解 谷歌浏览器xpath helper插件的安装和使用
3. xpath的节点关系
学习xpath语法需要先了解xpath中的节点关系
3.1 xpath中的节点是什么
每个html、xml的标签我们都称之为节点,其中最顶层的节点称为根节点。我们以xml为例,html也是一样的
 节点
节点3.2 xpath中节点的关系
 xpath中节点的关系
xpath中节点的关系author是title的第一个兄弟节点
4. xpath语法-基础节点选择语法
- XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
- 这些路径表达式和我们在常规的 电 脑文件系统中看到的表达式非常相似。
- 使 用chrome插件选择标签时候,选中时,选中的标签会添加属性class="xh-highlight"
4.1 xpath定位节点以及提取属性或文本内容的语法
表达式 | 描述 |
|---|---|
nodename | 选中该元素。 |
/ | 从根节点选取、或者是元素和元素间的过渡。 |
// | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. | 选取当前节点。 |
.. | 选取当前节点的父节点。 |
@ | 选取属性。 |
text() | 选取文本。 |
4.2 语法练习
接下来我们通过itcast的页面来练习上述语法:http://www.itcast.cn/
- 选择所有的h2下的文本
//h2/text()
- 所有的a标签的href
//a/@href
- html下的head下的title的文本
/html/head/title/text()
- html下的head下的link标签的href
/html/head/link/@href
知识点:掌握 xpath语法-选取节点以及提取属性或文本内容的语法
5. xpath语法-节点修饰语法
可以根据标签的属性值、下标等来特定的节点
5.1 节点修饰语法
路径表达式 | 结果 |
|---|---|
//title[@lang="eng"] | 选择lang属性值为eng的所有title元素 |
/bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
/bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
/bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
/bookstore/book[position()> 1] | 选择bookstore下面的book元素,从第二个开始选择 |
//book/title[text()='Harry Potter'] | 选择所有book下的title元素,仅仅选择文本为Harry |
Potter的title元素 | |
/bookstore/book[price> 35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title |
元素,且其中的 price 元素的值须大于 35.00。 |
5.2 关于xpath的下标
- 在xpath中,第一个元素的位置是1
- 最后一个元素的位置是last()
- 倒数第二个是last()-1
5.3 语法练习
从itcast的页面中,选择所有学科的名称、第一个学科的链接、最后一个学科的链接:http://www.itcast.cn/
- 所有的学科的名称
//div[@class="nav_txt"]//a[@class="a_gd"]
- 第一个学科的链接
//div[@class="nav_txt"]/ul/li[1]/a/@href
- 最后一个学科的链接
//div[@class="nav_txt"]/ul/li[last()]/a/@href
知识点:掌握 xpath语法-选取特定节点的语法
6. xpath语法-其他常用节点选择语法
可以通过 通 配符来选取未知的html、xml的元素
6.1 选取未知节点的语法
通配符 | 描述 |
|---|
- | 匹配任何元素节点。 node() | 匹配任何类型的节点。
6.2 语法练习
从itcast的页面中 http://www.itcast.cn/ ,选中全部的标签、全部的属性
- 全部的标签
//*
- 全部的属性
//node()
知识点:掌握 xpath语法-选取位置节点的语法
7. lxml模块的安装与使用示例
lxml模块是一个第三方模块,安装之后使用
7.1 lxml模块的安装
对发送请求的xml或html形式的响应内容进行提取
pip/pip3 install lxml
知识点:了解 lxml模块的安装
7.2 爬虫对html提取的内容
- 提取标签中的 文 本内容
- 提取标签中的 属 性的值
- 比如,提取a标签中href属性的值,url,进而继续发起请求
7.3 lxml模块的使用
- 导入lxml 的 etree 库
from lxml import etree
- 利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果的列表 html = etree.HTML(text)
ret_list = html.xpath("xpath语法规则字符串")- xpath方法返回列表的三种情况
* 返回空列表:根据xpath语法规则字符串,没有定位到任何元素
* 返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
* 返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath7.4 lxml模块使用示例
运行下面的代码,查看打印的结果
from lxml import etree
text = '''
div>
ul>
li class="item-1">
a href="link1.html">
first item/a>
/li>
li class="item-1">
a href="link2.html">
second item/a>
/li>
li class="item-inactive">
a href="link3.html">
third item/a>
/li>
li class="item-1">
a href="link4.html">
fourth item/a>
/li>
li class="item-0">
a href="link5.html">
fifth item/a>
/ul>
/div>
'''
html = etree.HTML(text)#href的列表和title的列表href_list = html.xpath("//li[@class='item-1']/a/@href")
title_list = html.xpath("//li[@class='item-1']/a/text()")#组装成字典for href in href_list:
item = {
}
item["href"] = href
item["title"] = title_list[href_list.index(href)]
print(item)8 练习
将下面的html文档字符串中,将每个class为item-1的li标签作为1条新闻数据。提取a标签的文本内容以及链接,组装成一个字典。
text = ''' div>
ul>
li class="item-1">
a>
first item/a>
/li>
li class="item-1">
a href="link2.html">
second item/a>
/li>
li class="item-inactive">
a href="link3.html">
third item/a>
/li>
li class="item-1">
a href="link4.html">
fourth item/a>
/li>
li class="item-0">
a href="link5.html">
fifth item/a>
/ul>
/div>
'''- 注意:
- 先 分组,再提取数据,可以避免数据的错乱
- 对于空值要进行判断
- 参考代码
from lxml import etree text = '''
- first item
- second item
- third item
- fourth item
- a href="link5.html"> fifth item
'''
#根据li标签进行分组html = etree.HTML(text)
li_list = html.xpath("//li[@class='item-1']")#在每一组中继续进行数据的提取for li in li_list:
item = {
}
item["href"] = li.xpath("./a/@href")[0] if len(li.xpath("./a/@href"))>
0 else None
item["title"] = li.xpath("./a/text()")[0] if len(li.xpath("./a/text()"))>
0 else None
print(item)知识点:掌握 lxml模块中使用xpath语法定位元素提取属性值或文本内容
10. lxml模块中etree.tostring函数的使用
运行下边的代码,观察对比html的原字符串和打印输出的结果
from lxml import etree
html_str = ''' div>
ul>
li class="item-1">
a href="link1.html">
first item/a>
/li>
li class="item-1">
a href="link2.html">
second item/a>
/li>
li class="item-inactive">
a href="link3.html">
third item/a>
/li>
li class="item-1">
a href="link4.html">
fourth item/a>
/li>
li class="item-0">
a href="link5.html">
fifth item/a>
/ul>
/div>
'''
html = etree.HTML(html_str)
handeled_html_str = etree.tostring(html).decode()
print(handeled_html_str)10.1 现象和结论
打印结果和原来相比:
- 自动补全原本缺失的
li标签 - 自动补全
html等标签
html> body> div> ul> li class="item-1"> first item/li> li class="item-1"> second item/li> li class="item-inactive"> third item/li> li class="item-1"> fourth item/li> li class="item-0"> fifth item /li> /ul> /div> /body> /html>
结 论:
- lxml.etree.HTML(html_str)可以自动补全标签
lxml.etree.tostring函数可以将转换为Element对象再转换回html字符串- 爬虫如果使用lxml来提取数据,应该以
lxml.etree.tostring的返回结果作为提取数据的依据
知识点:掌握 lxml模块中etree.tostring函数的使用
未完待续 下一期下一章
完整笔记请看文章开头
点击关注作者,阅读全文声明:本文内容由网友自发贡献,本站不承担相应法律责任。对本内容有异议或投诉,请联系2913721942#qq.com核实处理,我们将尽快回复您,谢谢合作!
若转载请注明出处: 【python爬虫笔记】0基础到scrapy高手,第(5)篇:爬虫数据提取之lxml和xpath
本文地址: https://pptw.com/jishu/572034.html